1. Problématique
L'accès à une information pertinente, adaptée aux besoins et au contexte de
l'utilisateur est un challenge dans un environnement Internet ou GRID,
caractérisé par une prolifération des ressources hétérogènes (données structurées,
documents textuels, composants logiciels, images. conduisant à des volumes
considérables. Au fur et à mesure que les masses de données s’accroissent
et que les types de données se diversifient, les systèmes de recherche
d’informations (moteurs web, SGBD, etc.) délivrent, dans des temps de
plus en plus longs, des résultats massifs en réponse aux requêtes des
utilisateurs, générant ainsi une surcharge informationnelle dans laquelle il
est souvent difficile de distinguer l’information pertinente d’une
information secondaire ou même du bruit. Par ailleurs, il est à remarquer que
l’évaluation des requêtes se fait sans tenir compte de
l’utilisateur qui les a émises ni du contexte d’où elles sont
émises. Généralement, les systèmes d’accès aux informations délivrent des
résultats en ne tenant compte que des seuls critères de sélection par le
contenu. Les centres d’intérêt récurrents des utilisateurs, leurs
préférences en qualité, en volume ou en présentation ne sont pris
en compte que dans la mesure où le langage de requêtes permet de les exprimer
et dans la mesure où l’utilisateur les formule systématiquement dans
chacune de ses requêtes.
Pour pallier à certains de ces problèmes, de nombreux travaux sont menés dans
diverses directions, en étendant les langages pour mieux capturer le caractère
imprécis ou approximatif des requêtes, en introduisant un ordre de préférence
dans les critères de sélection, en affinant les techniques de filtrage, en
aidant l’utilisateur à mieux exprimer ses besoins, en introduisant un ordre
qualitatif dans les résultats calculés ou en inventant de nouvelles techniques
d’indexation et d’optimisation. La plupart de ces travaux tendent
vers un objectif commun : délivrer, en un temps acceptable, une information
pertinente et de qualité en fonction de caractères spécifiques de
l’utilisateur.
La pertinence et la qualité de l’information ne sont cependant pas des
mesures objectives, généralisables à tout type d’informations et valides
pour tout type d’utilisateurs. Elles dépendent notamment du centre
d’intérêt ou domaine d’application, du moment, du lieu et du
support que l’utilisateur a choisi pour accéder à l’information et
du système qui délivre cette information. Elles peuvent concerner les données
elles-mêmes, les sources fournissant ces données, les processus de production
de ces données ou les trois à la fois. Le temps de réponse non plus n’a
pas une seule échelle de référence ; selon les applications, selon les
utilisateurs, le temps de réponse espéré ou acceptable pour une requête peut
être de l’ordre de la seconde, de la minute ou de l’heure.
Ce sont ces variations de préférence, de pertinence et de qualité qui
caractérisent un utilisateur ou un groupe d’utilisateurs que l’on
regroupe sous le terme de profil. On peut ainsi voir la personnalisation de
l’information comme un processus de définition, de construction et
d’utilisation des profils pour répondre de façon efficace et adaptée à un
même type de requête émis par des utilisateurs de profils différents.
Il convient de distinguer la notion de profil de la notion de requête. Un
profil peut être défini comme une mise en équation du centre d’intérêt et
des préférences de l’utilisateur, alors qu’une requête est
l’expression d’un besoin circonstancié que l’utilisateur
souhaite voir satisfait en tenant compte de son profil. Un profil a un
caractère plus invariant que les requêtes même si le centre d’intérêt et
les préférences de l’utilisateur peuvent légitimement évoluer. Un profil
peut être modélisé directement à partir des besoins et des préférences des
utilisateurs ou découvert par des méthodes de datamining ou
d’apprentissage à partir de leur comportement passé. Une requête est
définie systématiquement par l’utilisateur dans un langage formel ou via
une interface de haut niveau.
On peut aborder la personnalisation selon différents points de vue : soit à
travers les applications qui en ont besoin, soit à travers les technologies de
base qui permettent de développer ces applications.
- Les domaines d’application qui ont recours
à la personnalisation de l’information sont nombreux: le commerce
électronique (e-commerce), la dissémination sélective
d’informations, l’apprentissage assisté par ordinateur (e-learning), l’accès aux bibliothèques
électroniques (digital libraries), les systèmes
d’information mobiles (téléphonie mobile, agendas personnels,
systèmes embarqués), la (re)configuration de
logiciels (réseaux, composants), etc. Selon les domaines, la
personnalisation consistera en l’une ou plusieurs des tâches
suivantes : filtrer un flux d'informations entrant pour éliminer le bruit,
guider la navigation dans un espace d'informations trop vaste, recommander
un ensemble d'informations à l'utilisateur de manière plus intrusive
(nouvelles offres par exemple), ajuster le résultat d'une requête selon
une interface (ordre de présentation des résultats par exemple), adapter
l'interaction à la situation de l'utilisateur (matérielle, géographique),
etc.
- Parmi les technologies qui permettent de
supporter ces applications, on distingue entre autres les systèmes de
bases de données, les moteurs de recherche d’informations, les
interfaces homme-machine et les intergiciels (ou middlewares). Chacune de ces
technologies a une offre différente en personnalisation : introduction de
préférences dans les langages de requêtes, utilisation du
‘feedback’ des utilisateurs, pondération et ordonnancement des
résultats des recherches, exploitation d’ontologies, etc.
Ces deux points
de vue sont orthogonaux ; il convient de proposer des extensions aux
technologies de base pour une meilleure prise en compte de la personnalisation,
mais il faut aussi valider ses extensions par rapport aux domaines
d’application. C’est l’ambition que nous fixons au projet
APMD. La section suivante décrit les objectifs de ce projet.
2. Verrous scientifiques et
technologiques
Nous reprenons
les conclusions de l’AS98 sur la Personnalisation de
l’Information [REF ?]. En tant qu’outil,
Passage à l’échelle : L’un des principaux verrous auquel la
personnalisation de l’information peut apporter une solution est le
passage à l’échelle dans le contexte d’Internet ou du GRID. En
effet, dans ces environnements, les algorithmes d’évaluation de
requêtes actuels se trouvent très vite inadaptés en raison des volumes
considérables de données à traiter. Pour tenter de lever ce verrou, on fait
souvent appel à de nouvelles architectures de machines ou de systèmes
exploitant notamment le parallélisme et le haut débit. Il peut également être
levé par le biais de la personnalisation. En effet, un moyen de réduire
l’espace de recherche et la taille des résultats consisterait à augmenter
l’expressivité des langages de requêtes et à intégrer des profils pour
éliminer le plus tôt possible le bruit et les données les moins pertinentes. La
prise en compte de la qualité peut guider dans la sélection des sources
d’information et dans la production des résultats.
Evaluation qualitative : Du point de vue de l’utilisateur, la mesure de
la pertinence ou en général de la qualité des résultats produits est un point
essentiel de la personnalisation. On constate que la plupart des instruments proposés
concernent la mesure de qualité de la donnée produite par rapport aux critères
de la requête ou par rapport aux connaissances sémantiques caractérisant les
sources de données. Or dans certains cas (données dérivées par des fonctions
d’agrégat par exemple), cette mesure est impossible à faire et
l’utilisateur le sait. Dans ce cas, ce qui l’intéresse c’est
la qualification du processus de dérivation de la donnée plutôt que la donnée
elle-même (la qualité d’un indicateur statistique n’est pas facile
à déterminer si on ne connaît pas la méthode statistique qui l’a
produit). Sans instruments formels de l’évaluation de la qualité et de la
mesure de la pertinence, la personnalisation de l’information se
réduirait à la customisation des interfaces où la valeur ajoutée des systèmes
de recherche d’information reste mineure et en deçà des espérances des
utilisateurs.
Protection de la vie privée : La définition, l’utilisation et la
dissémination des profils sur le réseau constituent un formidable atout pour la
personnalisation de l’information. Cependant, elle peut introduire des
effets de bords pouvant dévoiler la vie privée des individus et atteindre à
leur liberté et à leurs droits. On ne peut donc mener une recherche sur la
personnalisation de l’information (le profilage des personnes) sans une
réflexion sur le droit des personnes. Nous avons mentionné précédemment que la
dimension «sécurité» du méta-modèle de profil permet
de spécifier des limites d’accès aussi bien sur les données accédées par
l’utilisateur que sur les données de profil lui-même ; encore faut-il que
les systèmes exploitant cette sécurité soient eux-mêmes architecturés selon une
norme qui garantit le respect des droits et qu’ils soient dotés de
protections nécessaires (firewall) pour empêcher
l’intrusion par d’autres systèmes ne respectant pas ce droit. La
personnalisation de l’information doit donc s’accompagner
d’une réflexion sur les architectures des systèmes de traitement
d’informations (couches fonctionnelles et protocoles de communication
bien identifiés), d’un effort de standardisation (protocoles de
communication et d’authentification) et de la définition de techniques
défensives (supports de stockage ou de calcul inviolables comme la carte à
puce, méthodes de cryptographie, modèles d’octroi ou de révocation de
droits). Les difficultés de cette réflexion résident souvent dans le fait que
les systèmes doivent à la fois être ouverts pour permettre la production de
certaines informations et fermés pour en empêcher la production d’autres.
Les objectifs fixés au projet APMD concernent les deux premiers verrous. Le
troisième relève en effet plus d’autres technologies que de la recherche
d’informations, comme les protocoles de sécurité sur les réseaux, la
cryptographie, les standards de certification, etc.
3. Objectifs du projet
Le projet APMD
(Accès Personnalisé à des Masses de Données) a pour objectif de mener une
réflexion globale sur la personnalisation de l’information dans un
environnement à grande échelle. Plus précisément, nous envisageons de proposer
des modèles formels capables de capturer les besoins des utilisateurs et de les
représenter dans des profils qui seront utilisés par des algorithmes robustes
pour un accès et une présentation adaptative de l’information. Nous mettrons
en évidence la relation forte qui existe entre la personnalisation et la
qualité de l’information, ainsi que leur utilisation conjointe pour un
accès efficace et efficient à l’information. Le projet se focalisera
particulièrement sur l’aspect évolutif des profils en intégrant notamment
le feedback de l’utilisateur via l’expression explicite de sa
satisfaction ou des préférences dérivées de son comportement.
Le projet est bâti autour de trois dimensions : la notion de profil et son mode
de représentation et d’élaboration, la qualité de l’information et
ses méthodes de mesure, le modèle d’exécution adaptatif des requêtes basé
sur les profils. Ces dimensions seront validées par une expérimentation
montrant l’influence verticale de la personnalisation sur les systèmes de
recherche d’informations. Le projet sera mené par des équipes ayant une
très bonne compétence en recherche d’informations ou en bases de données
et qui ont déjà commencé à développer une forte synergie entre elles dans le
cadre de deux actions spécifique CNRS sur les thématiques de la
personnalisation et du passage à l’échelle dans les SRI. L'approche que
nous proposons vise notamment (Figure 1) :
- une exploration systématique et aussi large que
possible de la notion de profil : de quoi est constitué un profil, comment
le construire, comment l’utiliser, comment le faire évoluer ;
- une définition des facteurs de qualité influant
sur la personnalisation : quels sont les facteurs de qualité liés à
l’information recherchée, aux sources fournissant cette information,
aux processus de production de cette information, aux modes
d’exécution des requêtes, au contexte d’interrogation de
l’utilisateur ;
- une définition d’un modèle adaptatif
d’exécution de requêtes : quelle partie du profil influe sur quelle
étape du cycle de vie d’une requête, comment est évaluée la qualité
lors de cette exécution, comment intégrer le feedback de
l’utilisateur, quelles traces garder pour justifier les réponses du
système, quelle influence ont le profil et la qualité sur la réduction de
l’espace de recherche.
Un des principaux atouts du consortium constitué autour de ce
projet est la maîtrise des techniques développées aussi bien dans le domaine de
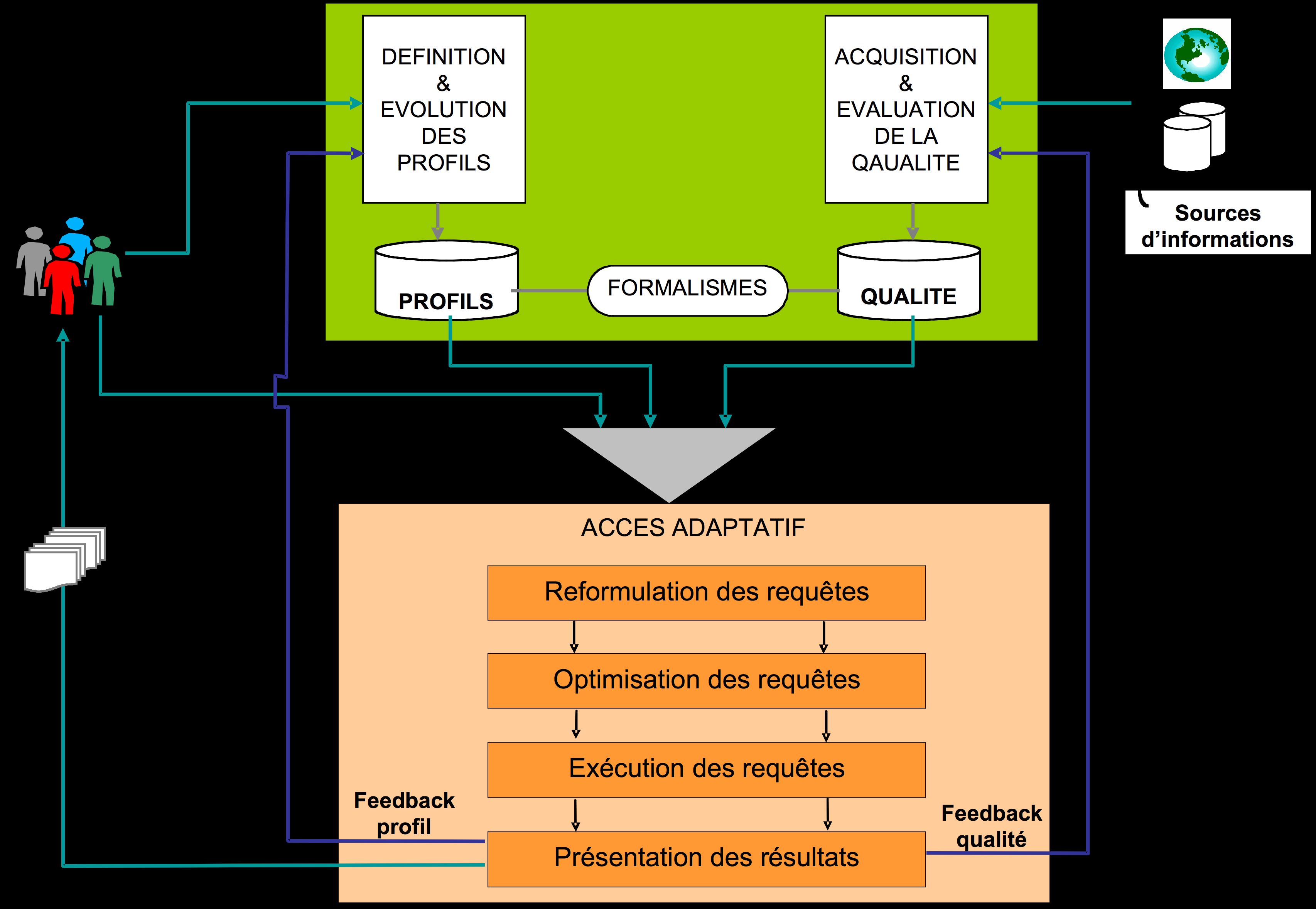
Figure 1 : Composants fonctionnels du
projet APMD